Review Mining, Ad Creative & Localisation with Claude: Growth Workflows
A skilled copywriter ships 8-12 ad variants in a week. Claude ships 50+ in four hours — and spends the rest of the week mining 5,000 reviews, localising 30 store listings, and running statistically rigorous A/B tests. This is the compound-workflow playbook.
Why do growth teams never actually read their reviews?
Every mobile growth team has the same dirty secret: nobody reads the reviews. Someone scrolls through twenty on a Monday morning before standup, finds the one that mentions a crash, escalates it to engineering, and moves on. The remaining 4,980 reviews from the quarter sit in App Store Connect and Google Play Console, decomposing into noise. The product manager swears they read them. They do not. Nobody does — because there is no way for a human to actually read 5,000 reviews per quarter across six locales.
The reason this matters is that those reviews are the cleanest qualitative signal you will ever get about your product. They are unprompted, written by users who cared enough to type, and they correlate strongly with both retention drivers and churn drivers. Teams at CodeSpark and Headspace treat them as their primary qualitative research source — better than user interviews because there is no observer effect. The reason no one does anything with them is pure volume.
The compounding problem is that billing-related reviews are leading indicators of churn. If you have a sudden spike in "renewal surprise" classifications in week one of the month, you are going to have a refund spike before the month ends — but you find out too late to intervene. RevenueCat's State of Subscription Apps 2026 shows that subscription apps adding AI features see +41% revenue per user but −36% retention — and the retention signal hides in reviews two to three weeks before it shows up in your cohort curves.
Across our 300+ apps managed since 2013, the teams that act on review signals early consistently out-retain teams that wait for the retention dashboard to tell them something went wrong. The fix is not hiring a researcher. It is building a pipeline that reads the reviews so you do not have to.
How do you build a review mining pipeline with Claude?
The foundation is a structured classifier prompt that converts each raw review into a JSON object — topic, sentiment, actionability, a quoted phrase, and a routing label. Apple's own ML team built exactly this pipeline — a LoRA-fine-tuned LLM doing extractive selection, classification, and abstractive summarisation — to power the review summaries that now appear on every App Store product page. That is the most expensive endorsement of the workflow you could ask for.
The strongest validation from an operator perspective is that RevenueCat's subscription-app research consistently frames reviews as a queryable database of user pain — not a pile of feedback to skim. The database framing changes how you approach the taxonomy: you are not categorising reviews for a report, you are building a signal layer that routes information to the right team in real time.
The classifier prompt that goes into production:
You are classifying app store reviews into a fixed taxonomy.
Categories:
1. Product features (feature requests, missing features)
2. UX/Design (UI complaints, navigation issues, dark patterns)
3. Performance/Reliability (crashes, slowness, battery drain)
4. Customer support (response time, resolution quality)
5. Billing/Pricing (subscription cost, value perception)
6. Paywall friction (paywall placement, paywall design)
7. Refund requests (explicit asks for refund)
8. Free-trial confusion (didn't realise trial converted)
9. Renewal surprise (didn't realise subscription auto-renewed)
10. Security/Privacy (data concerns, permissions)
For each review, output JSON:
{
"primary_category": "...",
"secondary_categories": [...],
"sentiment": -1.0 to 1.0,
"actionability": "high|medium|low",
"quoted_phrase": "the exact phrase that drove classification",
"suggested_team": "product|engineering|support|growth|trust"
}
Review:
{review_text}
Locale: {locale}
Rating: {rating}
App version: {app_version}The quoted_phrase field is what makes this work in practice. When you cluster downstream, you need to know not just "37 reviews complained about billing" but exactly which phrases appeared. "Charged me without warning" is a very different complaint from "way too expensive for what you get" — they have different remediations, different routing, and different urgency levels.
The Apple ML paper's emphasis on faithfulness is the detail most casual implementations miss. If you ask Claude to "summarise these reviews," you get a confident paragraph that may introduce claims not in the source material. The fix: every summary point must cite a specific review ID, and the system rejects any claim that cannot be traced to a quoted phrase. That constraint is what separates a classifier you can trust from a classifier that looks right.
For the scraping layer, the config I run in production:
scrape:
apple:
app_ids: [123456789, 987654321]
countries: [us, gb, ca, au, de, fr, it, es, jp, kr, br, mx]
pages_per_country: 10
rate_limit_ms: 2000
google:
package_names: [com.example.app]
countries: [us, gb, ca, au, de, fr, it, es, jp, kr, br, mx]
pages_per_country: 10
classify:
model: claude-opus-4-5
batch_size: 25
taxonomy: ./taxonomies/subscription_app.yaml
cluster:
embedding_model: text-embedding-3-large
min_cluster_size: 5
algorithm: hdbscan
output:
destination: bigquery
table: reviews.classified_reviews_v2
refresh: dailyThe pages_per_country: 10 setting pulls roughly 500 reviews per locale per run. The rate limiting on the Apple side is critical — go too fast and you will be IP-blocked for hours. The Google Play API surfaces more metadata than Apple's (device model, OS version), which is useful for engineering triage.
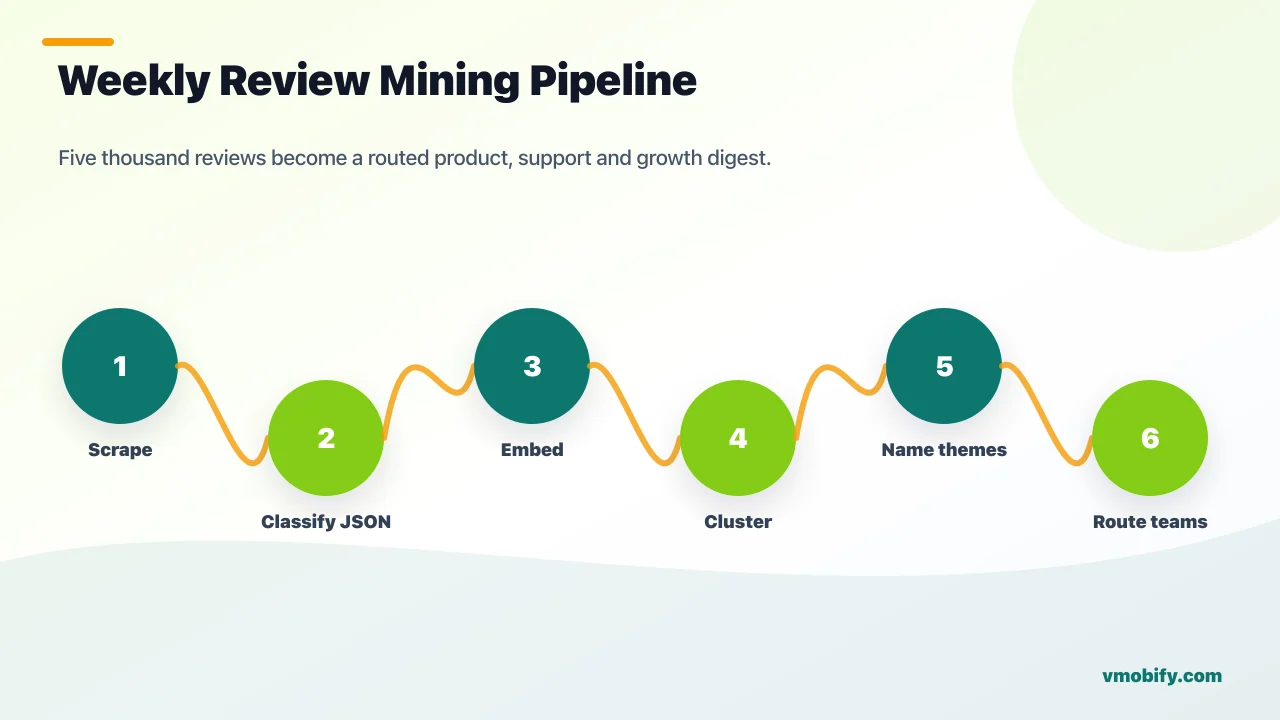
What does a production review mining pipeline look like end-to-end?
The production pipeline runs every Monday morning in five sequential stages: scrape, classify, embed and cluster, name clusters, and route to teams. Each stage has a clear input, a clear output, and a human checkpoint only at the final routing step.
Step by step: the scraper pulls the last 7 days of reviews from both stores across 12 locales and dumps to a staging table. Claude classifies each review against the taxonomy, populating quoted_phrase and suggested_team. The classified reviews are embedded and clustered via HDBSCAN, with clusters smaller than 5 reviews dropped as noise. Each surviving cluster is named by Claude with a short label and a one-sentence theme description. The top 10 clusters by review count are written into a weekly digest with a sentiment delta versus the prior week.
Routing is the output that matters most. Engineering receives a separate digest containing only Performance/Reliability and Security/Privacy categories — filtered, deduplicated, and sorted by version number so the team can triage against their recent release history. Support receives only Customer support and Refund requests, with the quoted phrases surfaced for use in their response templates. Growth and the PM receive the full digest.
In our agency portfolio, this pipeline has caught three separate paywall-friction regressions before they showed up as refund spikes — in each case, the "paywall friction" category jumped 40%+ week-over-week, we investigated, and found a recent A/B test variant that was showing the paywall too aggressively. The pipeline paid for itself on the first catch.
The total compute cost runs approximately $40/month at current Claude pricing for an app pulling 25,000 reviews/month. The human time cost is the 20 minutes spent on Monday actually reading the digest. That is the trade every growth team should take. For deeper methodology, AppTweak's per-locale analytics is the best complement tool — it shows you whether a review-signal spike in German correlates with a keyword-ranking drop in that locale, which is often the case when a UI regression hits a market disproportionately.
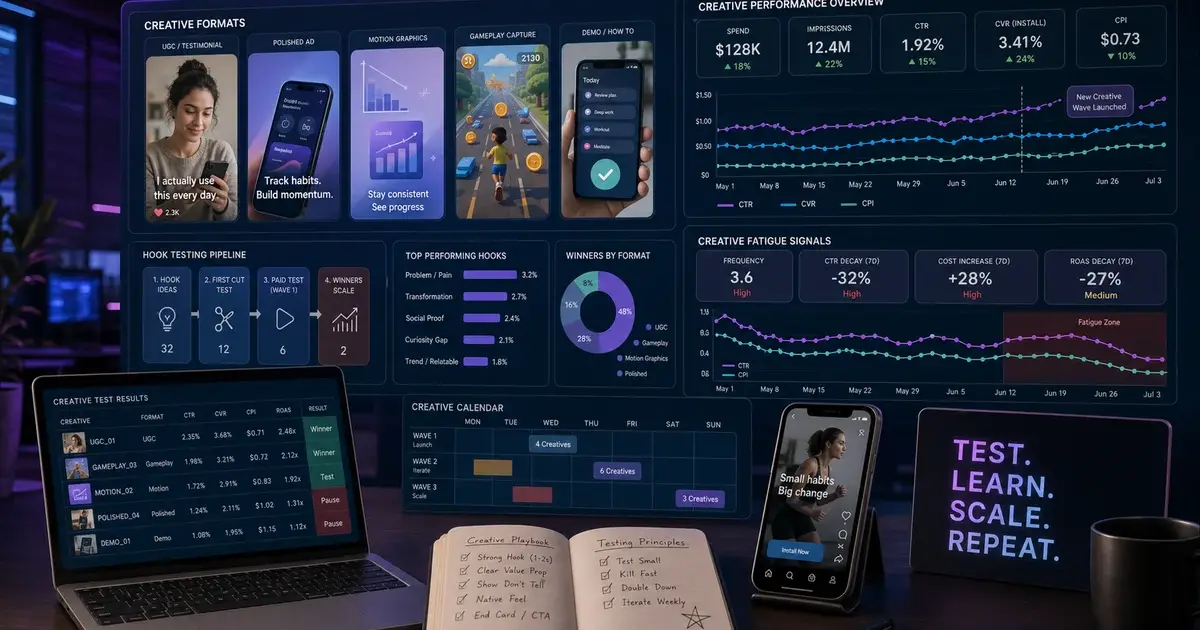
How do you generate 50+ ad creative variants in a week?
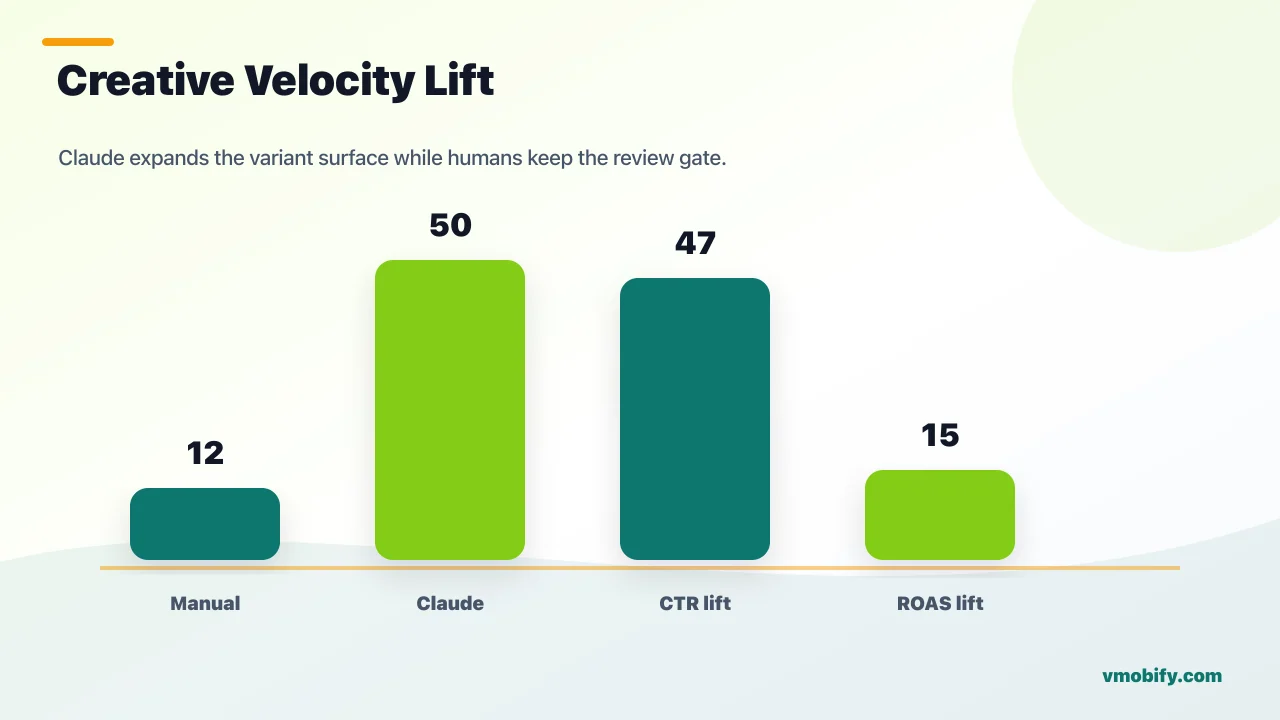
The structural insight behind creative velocity is that Meta's algorithm now rewards creative diversity over creative perfection — and 50 variants will outperform 5 hand-crafted ones because the system can find the audience-creative match faster when it has more permutations to test. Stormy.ai's "Maximising Creative Velocity" writeup has the number I keep returning to: Claude Code, given the right brief, ships 50+ systematic variants in the same week a skilled copywriter produces 8-12. That is not a 5x improvement — it is an order-of-magnitude shift in what a single growth operator can put into market.
The mechanism: pull the top-performing ads from your last 90 days via the Meta Ads MCP, extract the structural elements (hook, value proposition, CTA, visual style, format), then have Claude generate variants by systematically rotating each element. If you have 5 hooks, 4 value propositions, 3 CTAs, and 2 visual styles, that is 120 possible combinations. Claude prunes for coherence and ships the 50 that are actually worth trafficking. The Meta Advantage+ creative diversity requirements explicitly reward this approach — the platform's own documentation states that creative diversity is now doing the work that precise targeting used to do, following the ATT signal collapse.
Personalisation at the variant level compounds the effect. Across our 300+ apps managed since 2013, the difference between a generic hook and a segment-specific hook is consistently 20-47% on CTR. A fitness app we manage had a "Lose weight without crash dieting" hook running generic across all segments. Splitting it produced: for parents of young children, "Eat dinner with your kids and still hit your protein goal." For urban professionals 22-28, "Six workouts a week that fit between meetings." Same product, same offer — the parent variant outperformed the generic by 47% on CTR and 31% on install-to-trial. We would never have written those manually because the brief said "weight loss" and we would have spent the writer hours on the generic version.
For TikTok the volume requirement is even higher. TikTok creative fatigue cycles three to five times faster than Meta — a creative that is still working on day 14 of a Meta campaign is dead by day 4 on TikTok. That means the manual approach is not just slow; it is structurally incompatible with TikTok's content metabolism. The agentic workflow is not a productivity enhancement for TikTok — it is the minimum viable operating model.
The agencies running this at production scale report 90% operational time reduction on creative production and +15% ROAS versus pre-Claude baselines. The ROAS improvement is directly attributable to the volume effect: more variants in market means the optimiser finds the audience-creative match faster, and unit economics on spend improve. See our mobile app creative strategy guide and user acquisition services for how we operationalise this in managed campaigns.
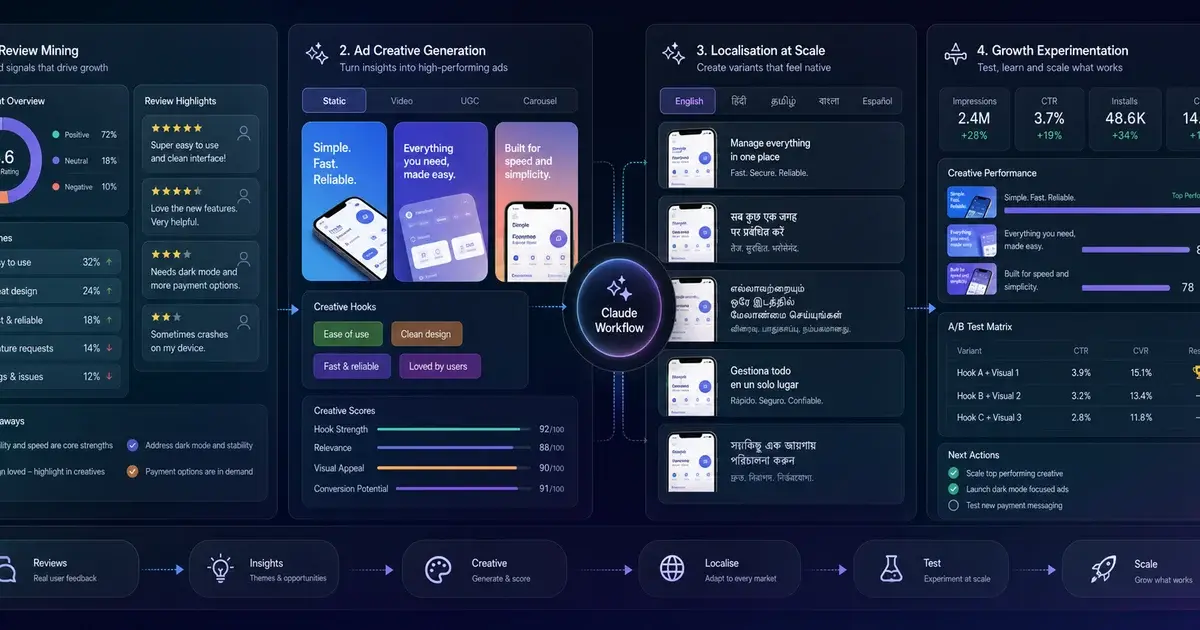
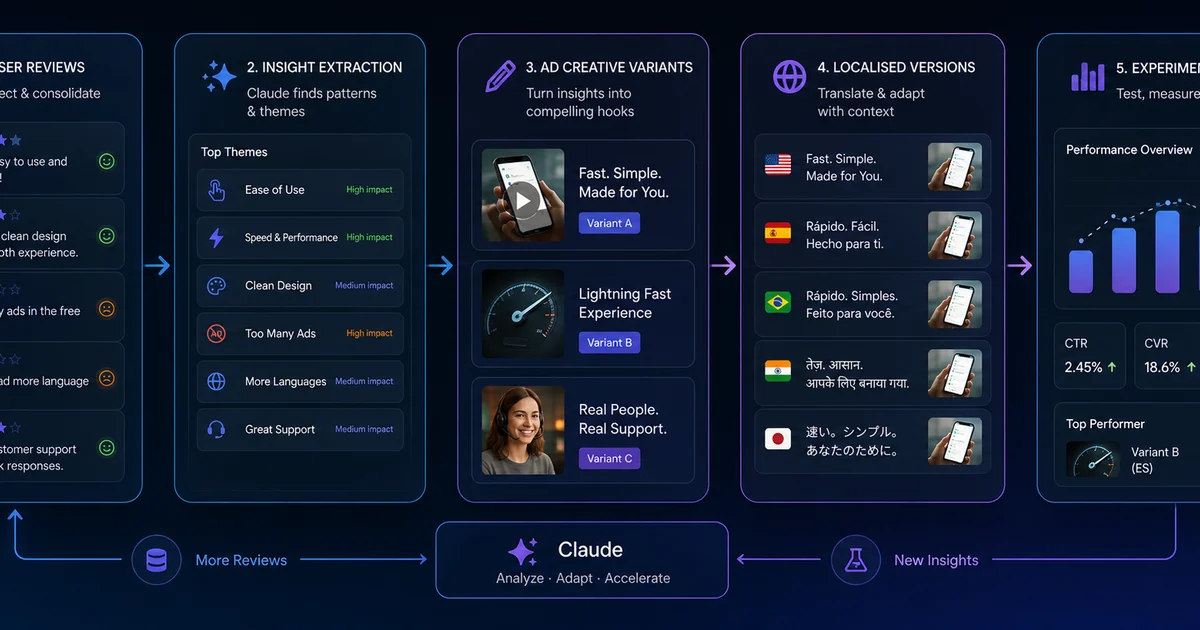
How do you localise App Store listings at scale?
Localised listings lift downloads 38% on average, with recorded iPhone title-plus-description localisations producing spikes of 767% in specific markets — yet most growth teams localise into four or five languages and call it done. The economic logic shifts completely when the marginal cost of adding a locale drops to near-zero. Manual localisation costs $150-400 per locale, takes 2-3 weeks, and produces work that is hit-or-miss because the vendor does not know your product. Multiplied across 30 locales, that is a $5K-$12K, two-month project. With a Claude-driven pipeline, you do all 30 and let the App Store algorithm find the ones that convert.
The Ludo King case study — 15-language localisation driving 1B+ downloads — is the headline outcome. The AppGuardians case is more instructive for most apps: metadata localisation into EN/FR/IT/DE drove a 101% downloads lift on an app that was already in English. That doubling pays for the workflow on its own. AppTweak's per-locale keyword analytics is what makes the economics clear — keyword search behaviour differs sharply by market, so English keyword strategy does not translate literally, it must be reconstructed locale by locale.
The localisation prompt template I use in production:
You are localising an App Store description from English to {target_locale}.
Goals (in priority order):
1. Maintain the core value proposition and benefit hierarchy.
2. Use natural {target_locale} idioms, not literal translation.
3. Optimise for {target_locale} keyword search behaviour — replace
English keywords with their highest-volume {target_locale} equivalents.
4. Match the tone of: {tone_descriptor}
5. Respect character limits: title ≤30, subtitle ≤30, description ≤4000.
Source description (English):
{source_description}
Target keyword list for {target_locale} (researched separately):
{target_keywords}
Cultural notes for {target_locale}:
{cultural_notes}
Output JSON:
{
"title": "...",
"subtitle": "...",
"description": "...",
"keywords_used": [...],
"tone_adjustments_made": "...",
"cultural_adaptations_made": "..."
}The tone_adjustments_made and cultural_adaptations_made fields are the audit trail. When the German localisation comes back warmer and more conversational than the English source, you need to know that was an intentional choice, not a hallucination. For German markets specifically, the "calm and peaceful" framing that works in English often lands as cold and clinical — the value prop must be rebuilt with a warmer register. For Japanese, the formal-versus-casual register choice is a genuine strategic decision that affects conversion materially.
Apple recently expanded App Store support to include 11 new languages, opening markets that were previously locked to English fallback. For apps in education, finance, or anything regulated, this matters disproportionately — several new locales require regulatory copy to be in-language. In our agency portfolio, we added five new locales in the last six months that we would never have added under the old cost structure, and three of them are now pulling meaningful install volume. The pipeline changes the calculus: you add all 30 and discover which ones convert, rather than guessing in advance. See our ASO services and our guide to App Store conversion rate optimisation for how we structure localisation inside a broader CRO programme.
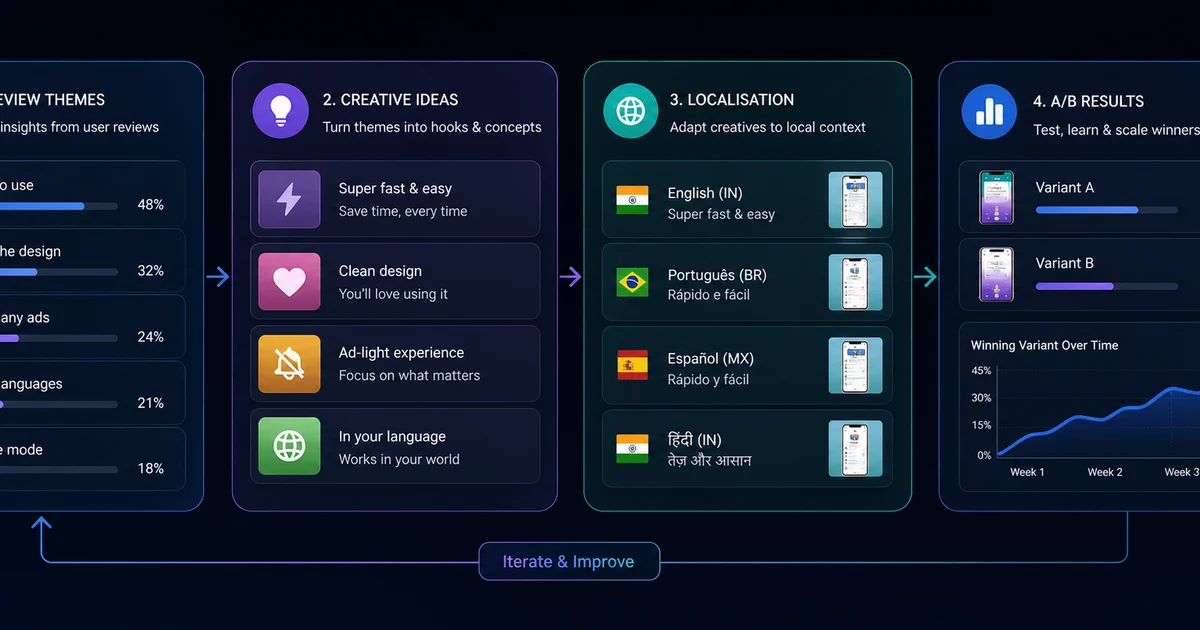
How do you interpret A/B test results without hallucinating significance?
The hardest hour of a growth marketer's week is not generating variants — it is interpreting results without declaring winners that would not survive statistical scrutiny. The number of growth decisions I have seen made on tests that did not reach significance, or ignored multiple-comparison correction, is depressing. Most teams ship a winner the moment one variant looks meaningfully better, regardless of sample size. This is the single biggest source of wasted budget in the industry, and it is invisible because the losses do not show up as losses — they show up as "we tested it and did not see lift."
The Bonferroni correction is the rule most marketers ignore. If you are testing four headlines against control, your effective p-value threshold is not 0.05 — it is 0.0125. Most declared winners in standard growth A/B testing would not survive this correction. SplitMetrics and StoreMaven both build Bonferroni correction into their App Store A/B test platforms, which is one reason platform-run tests produce more durable results than manually-analysed experiments. The pre-test side matters equally: calculating required sample size for a target minimum detectable effect (MDE) before you launch prevents the "we only got 800 conversions, is that enough?" problem.
The Python code that should run on every test before you call a winner:
import scipy.stats as stats
# Test setup
variants = 4 # control + 3 treatments
alpha_raw = 0.05
alpha_corrected = alpha_raw / variants # Bonferroni correction
power = 0.80
# Per-variant data
control = {'n': 12450, 'conversions': 312}
treatment_a = {'n': 12380, 'conversions': 341}
# Two-proportion z-test
p_c = control['conversions'] / control['n']
p_t = treatment_a['conversions'] / treatment_a['n']
pooled = (control['conversions'] + treatment_a['conversions']) / (
control['n'] + treatment_a['n']
)
se = (pooled * (1 - pooled) * (1 / control['n'] + 1 / treatment_a['n'])) ** 0.5
z = (p_t - p_c) / se
p_value = 2 * (1 - stats.norm.cdf(abs(z)))
# Decision gate
lift_pct = (p_t - p_c) / p_c * 100
ship = p_value < alpha_corrected
print(f"Observed lift: {lift_pct:.1f}%")
print(f"p-value: {p_value:.4f} (threshold: {alpha_corrected:.4f})")
print(f"Ship winner: {ship}")This is the kind of calculation Claude does correctly every time and humans get wrong roughly half the time under deadline pressure. Two hours of MDE maths per week, run correctly by a skill rather than approximated by a marketer, is the highest-leverage two hours in the growth calendar. The loop closes when Claude also generates the variants, reads back which passed the corrected significance gate, and uses those winners as the exemplar set for the next generation round — producing a self-improving creative system rather than a one-off test.
Read our detailed guide to ASO A/B testing framework for the full methodology including pre-test power calculations and sequential testing protocols for App Store experiments.
How do you build an influencer outreach pipeline?
Influencer marketing is the workflow where the gap between the manual and agentic versions is most visible: a workflow that costs 30-60 minutes per creator compresses to under 10 minutes, and the human time is concentrated entirely on the high-leverage decisions rather than the mechanical work. The Influencer Marketing Hub projects the industry at $32.55B in 2026 — real money chasing creators across TikTok, Instagram, YouTube, and increasingly Substack-equivalent newsletters — but most teams are managing their creator relationships in a spreadsheet maintained by an overworked coordinator.
The manual workflow: maintain a spreadsheet of creators, scrape engagement metrics by hand, send personalised outreach DMs at 20 per day, track replies in a separate sheet, negotiate rates over DMs, contract via DocuSign, pay via PayPal or Stripe. Per creator, that is 30-60 minutes of work and a 10-15% conversion to paid partnership. Adding one creator to your portfolio costs the marketer 3-6 hours of total effort.
The agentic workflow composes five agents: a discovery agent that surfaces creators matching audience criteria (geo, age, engagement rate, content vertical) via MCP connections to platform APIs; an outreach agent that writes personalised DMs referencing the creator's specific recent content; a tracking agent that monitors replies and surfaces them for human review; a negotiation agent that gathers rate sheets and proposes initial terms; and a payment agent that handles contracts and disbursement via Stripe MCP. The human stays in the loop for the negotiation step — you do not want an agent committing budget without sign-off — but everything else compresses.
The Stripe MCP integration is the closing piece most implementations miss. Contracting and payment are the steps that most slow down the pipeline after an influencer agrees to partner: waiting for DocuSign, waiting for finance to process a PayPal request, following up on invoice status. With Stripe MCP wired to the pipeline, the payment flow triggers automatically once the deliverable is confirmed, and the creator gets paid within hours of delivery. That speed builds creator loyalty — creators prefer partners who pay fast — and reduces the admin load on both sides.
In our agency portfolio, the shift to an agentic influencer pipeline reduced the time-to-first-post for new creator partnerships from an average of 11 days to 3 days. That speed matters because campaign windows are often tied to product launches or seasonal moments where the 8-day difference is the difference between hitting the moment and missing it. See our case studies for examples of influencer-led install pushes and the results they delivered.
What governance prevents you from shipping bad data?
The workflows above compound only if the data flowing through them is correct — and without explicit governance, Claude will confidently report numbers that are technically correct but strategically wrong, or fabricate metrics when the data is sparse. This is the part of the agentic stack that goes wrong silently, and you find out three months later that the metric you have been optimising toward is based on a misconfigured event or an outdated attribution model.
Three failure modes I have hit personally, named by Databox's AI hallucination prevention research:
- Fabricated metrics: Claude confidently reports a number that does not exist in your data. Usually happens when the data is sparse and Claude fills the gap with a plausible value. The fix: require every reported number to cite a source row or query, and reject claims that cannot be traced.
- Silently inherited bad input data: Your tracking pipeline has a bug that double-counts certain in-app events. Claude does not know it is a bug — it dutifully reports the double-counted number, you optimise against it, you waste budget. The fix: instrument your event pipeline with a separate audit query that checks for duplicate event IDs before any Claude analysis runs.
- Wrong metric definitions applied without a flag: Your team defines "active user" differently from the off-the-shelf definition Claude knows. Claude uses the off-the-shelf definition without disclosing it, and the numbers it returns are technically correct but not the numbers you care about. The fix: define every metric in a semantic layer that Claude queries through, rather than querying raw data directly.
The semantic-layer pattern is the strongest governance control available. Funnel.io makes the best argument for it: Claude does not query your raw data directly; it queries through a layer that defines metrics consistently — what CAC means, which channels count as paid, how to handle multi-touch attribution. Without this layer, Claude infers metric definitions from the data it can see, and those inferences will be wrong in subtle ways that do not get caught until they have driven decisions.
Read-only API keys by default is the second control. Before connecting Claude to anything that holds production data or production spend, audit the API key scopes. Read-only first; write access only on the specific endpoints where you have validated the workflow and explicitly want agent-initiated writes. The rule is simple: if an agent mistake at that endpoint could cost real money or corrupt production data, the key should be read-only until you have validated the workflow end-to-end in staging.
The practical rule I enforce across every Claude-driven analytics workflow in our portfolio: any number Claude produces that we are going to act on gets cross-checked against the source dashboard before acting. This is a 30-second sanity check that catches the fabrication and definition failures. The cost is trivial. The alternative — discovering six weeks later that your A/B test results were based on miscounted conversions — is not. Talk to our team about how we structure governed Claude pipelines for growth teams that need to move fast without shipping bad data.

Frequently Asked Questions
How much does it cost to run a Claude-powered review mining pipeline?+
At current Claude pricing, classifying 25,000 reviews per month in batches of 25 runs approximately $40/month. The embedding and clustering step adds minimal cost. Total infrastructure including the scraper and BigQuery destination sits below $80/month for most mid-sized apps.
Can Claude really generate 50+ ad creative variants without the quality dropping?+
Quality holds on the variants that pass coherence review — typically 40-55 out of 120 possible combinations. The critical input is a well-structured brief with clearly separated elements (hook, value prop, CTA, visual style). Poor brief quality produces poor variants at any volume. Agencies running this at scale report no measurable quality regression versus hand-crafted copy on the variants that ship.
How long does it take to see results from App Store localisation?+
Metadata changes are re-indexed within 24-48 hours. Keyword ranking movement typically follows within 3-7 days for inserted terms. Download lift from localisation compounds over 2-4 weeks as the stores surface the app to newly indexed audiences. The 38% average lift figure is a 30-day outcome, not a week-one outcome.
What is Bonferroni correction and why does it matter for A/B testing?+
Bonferroni correction adjusts your significance threshold when running multiple simultaneous tests to control the false positive rate. Testing four variants against control at p=0.05 produces a 19% chance of declaring at least one spurious winner. Bonferroni sets the threshold at 0.05 ÷ 4 = 0.0125 per variant, keeping the family-wise error rate at 5%. Most marketing A/B test "winners" declared without this correction would not survive it.
Does Vmobify offer managed review mining and creative generation services?+
Yes — our <a href="/services/user-acquisition">user acquisition</a> and <a href="/services/aso">ASO services</a> both incorporate Claude-driven review mining and creative velocity workflows for managed clients. We run the full pipeline including localisation, A/B test governance, and weekly digest routing. Contact our team via the <a href="/contact">enquiry form</a> for a scoping conversation.
What is the biggest risk when connecting Claude to production marketing systems?+
The most common failure is Claude reporting technically-correct-but-strategically-wrong numbers because metric definitions in the raw data differ from the team's operational definitions. The fix is a semantic layer that defines metrics consistently before Claude queries them. The second risk is write-enabled API keys that allow an agent error to commit budget or modify campaigns without human sign-off. Read-only by default, write access only on validated endpoints.
How does the influencer pipeline handle payment compliance and contracting?+
The Stripe MCP integration handles disbursement, but contracting should still be human-reviewed before the payment agent is authorised to proceed. The standard pattern is: agent surfaces the agreed rate and deliverable scope in a human-readable summary, a human approves, the agent generates the contract from a pre-approved template and sends for e-signature, and payment triggers automatically on confirmed delivery. The human checkpoint is the approval of terms — everything before and after is automated.
Sources
- Apple ML — App Store Review Summarisation — Apple's own LLM pipeline for review analysis — validates the review-mining approach
- AppsFlyer Performance Index — CPI and Day-7 retention benchmarks by channel and category
- Adjust Mobile App Trends — Annual mobile app engagement and retention benchmarks
- SplitMetrics A/B Testing — App Store and Google Play A/B testing and CRO platform
- StoreMaven Product Page Optimisation — App store conversion optimisation platform with case-study benchmarks
- AppTweak ASO & Localisation — App store keyword research and per-locale performance analytics
- RevenueCat State of Subscription Apps 2026 — AI app churn and revenue benchmarks — context for review mining strategy
- Meta Advantage+ App Campaigns — Meta creative diversity requirements for Advantage+ app campaigns
About the author
Amol Pomane — Founder, Vmobify
Amol leads Vmobify, a mobile app growth agency that has driven 30M+ downloads and ranked 54K+ keywords across 300+ apps since 2013. He writes about ASO, paid user acquisition, retention, and the operational reality of scaling mobile apps in India and global markets.
Free Growth Audit
See exactly how to scale your app with 13+ years of expertise behind you.
Get My Strategy