ASO Automation with Claude Code: The Complete 2026 Guide
Traditional ASO tooling was replaced by a Claude skill stack in 2026. This guide covers the seven layers of automated ASO — keyword research, metadata generation, screenshot copy, localisation, competitor intel, review mining, and rejection prevention — and the five skill repos driving the shift.
What changed in May 2026 that makes traditional ASO obsolete?
Two numbers published in the spring of 2026 rendered most existing ASO playbooks obsolete — and the operators who saw them as connected, rather than separate stories, are now running circles around those who did not.
The first: on 14 May 2026, both the Apple App Store and Google Play updated their ranking models to reweight retention signals over raw download volume. Apple is now dialling up the weight of post-install engagement; Google is doing the same with its quality scores in Play Console. A 10,000-install spike from a paid burst means substantially less than it did six months ago. What the algorithm cares about is whether those installs are still launching the app on Day 7. The entire optimisation function moved one step downstream.
The second: in early March 2026, Gummicube reported that Claude AI secured the #1 spot on the US App Store ratings chart, with 240% download growth over the prior quarter. Anthropic's consumer app did not win the store by buying installs. It won because users were rating it, retaining on it, and coming back to it — which is precisely what the new algorithm rewards. Appfigures estimated Claude's consumer mobile revenue at roughly $76M in April 2026 alone. That is a category that did not exist three years ago dominating a chart that used to belong to mobile games and dating apps.
The story these two numbers tell together: AI is rewriting how ASO is done, and AI products are also the apps that are winning ASO. Those two things are not a coincidence. They are the same shift. Traditional ASO — manual keyword spreadsheets, character-count discipline enforced by copy editors, monthly competitor check-ins, a freelancer for localisation — is too slow, too fragmented, and too shallow to compete with the new algorithm's demands. The operators winning in 2026 have built a coherent automation stack. This guide is that stack.
Across our 300+ apps managed since 2013, we have tracked every major algorithm update both stores have shipped. May 2026 is the single most consequential shift since Google introduced Play Integrity scoring in 2022. Apps that have not updated their listing strategy since late 2025 are already losing ground to those that have — and they typically will not know it until their organic install rate has declined 20-30% before anyone notices. If you use our ASO service, we have already updated your listing strategy for the new model. If you are running ASO in-house, what follows is the new playbook.
What does ASO automation actually mean in 2026?
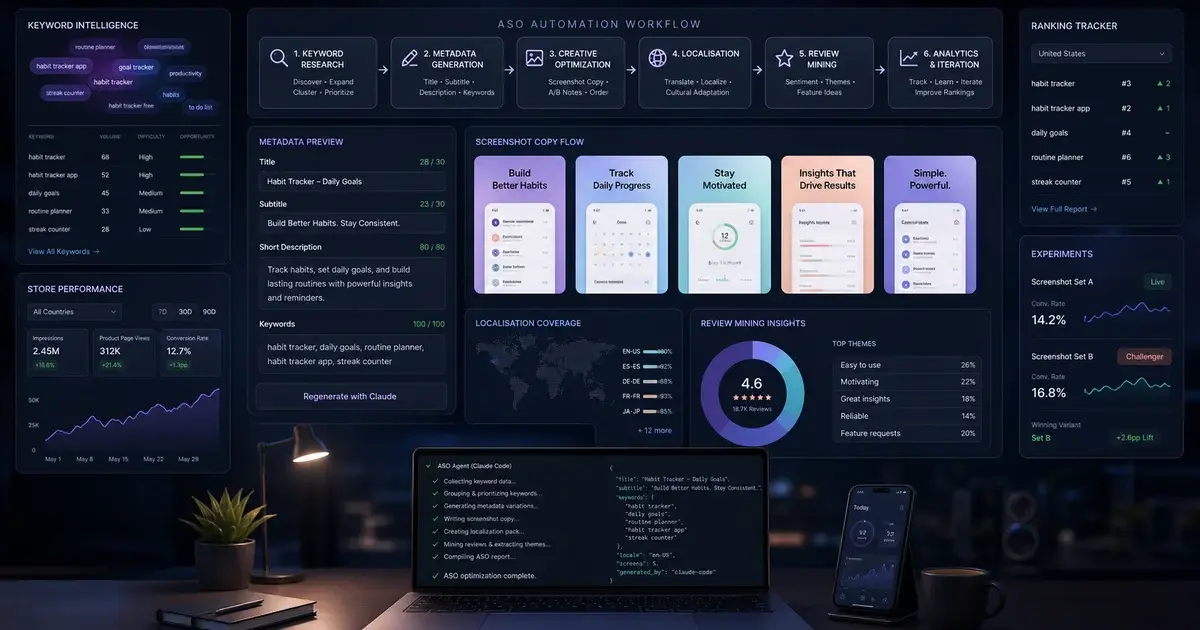
ASO automation in 2026 does not mean a button you push that magically optimises your listing — it means a coherent set of operator workflows, each of which used to take a human a day or a week, each of which is now a Claude skill that runs in minutes against live data.
The work decomposes into seven distinct layers:
- Keyword research — discovery, volume estimation, ranking volatility tracking, gap analysis against competitors.
- Metadata optimisation — title (30 chars), subtitle (30 chars), keywords field (100 chars), description (4,000 chars), with every character counted precisely.
- Screenshot and caption strategy — the visual conversion surface, which is now the single highest-leverage element on the store page.
- Localised listings — not "translate the title" but a full per-locale ASO strategy in 30+ languages, each independently keyword-researched.
- Competitor intelligence — pulling rivals' metadata, ranking history, recent updates, and review keyword clusters.
- Review mining — extracting feature requests, bug clusters, and sentiment swings from the review stream.
- Rejection prevention — pre-flight checking submissions against the Apple Review Guidelines before you hit submit.
Each of these was previously a separate tool, a separate dashboard, a separate retainer. In 2026, each is a Claude skill, and the better operators are composing them into a single coherent sprint. Eric Seufert framed this on Mobile Dev Memo: the AI-enabled mobile growth stack is the dominant operating mode this year, and the marketers who refused to adopt it spent 2025 explaining away flat KPIs. The discipline did not get easier — it got more concentrated. Fewer humans, more leverage per human, sharper outputs per hour.
The critical insight is that these seven layers are not independent tasks — they are one system. Keyword research informs metadata generation; metadata generation informs screenshot copy; screenshot copy informs localisation priorities; localisation output feeds into rejection prevention checks. The operators who build them as a connected pipeline rather than a series of ad-hoc prompts are the ones getting the leverage the discipline now offers. See our full breakdown of how we approach this for clients at Vmobify's ASO service page.
Which ASO skill repos should every operator know?
Five repos constitute the spine of the 2026 ASO skill stack — each approaches the problem from a different angle, and together they cover all seven automation layers.
1. Eronred/aso-skills is the most platform-shaped of the group. It bundles AI agent skills for ASO and app marketing — keyword research, metadata writing, competitor analysis — and is powered by the Appeeky API for live store data. It plays well with both Claude Code and Cursor. The trade-off: you are dependent on Appeeky's API for underlying data, which is fine if you trust their coverage and rate limits.
2. alirezarezvani/claude-code-aso-skill is the one we keep recommending to senior operators. It is an AEO (App Engine Optimisation) automation framework with four sub-agents orchestrating around a master: aso-master (the orchestrator), aso-research (keyword discovery, volume estimation, trend detection), aso-optimizer (character-aware metadata writing), and aso-strategist (competitive positioning). It uses the iTunes Search API plus WebFetch calls for competitor intel — no paid SaaS dependency. For a small app team that does not want to pay for AppTweak or Sensor Tower, this stack covers roughly 80% of what you actually need at zero marginal cost beyond Claude tokens.
3. dock-aso/aso-optimizer-skill is the most opinionated workflow. It enforces a strict three-stage pipeline: keyword discovery first, then metadata optimisation, then competitor research. The discipline of that ordering matters more than it sounds — operators routinely write metadata before doing the keyword work, and they wonder why their listings rank for nothing. We use dock-aso when onboarding a new app and wanting to enforce the right sequence with a junior teammate.
4. TimBroddin/app-store-aso-skill focuses tightly on Apple's App Store. The killer feature is character-limit validation: the skill refuses to output a title over 30 characters, refuses a subtitle over 30, and so on. If you have ever submitted a listing only to have App Store Connect reject your subtitle for being 31 characters because of a smart quote, you understand why this matters. We treat TimBroddin as the "metadata enforcement layer" in a larger stack rather than as a standalone tool.
5. cruisediary/apple-app-review-skills is special. It is a rejection-prevention skill with 31 specific checks built from real rejection cases, spanning all five sections of the Apple Review Guidelines — Safety, Performance, Business, Design, and Legal. Every meaningful failure mode we have personally hit in the last three years has a check in this skill. We dedicate a full section to it below because it is arguably the highest-ROI skill in the entire stack in 2026.
For a broader view of what is available, the App Store Optimisation skill on SkillsDirectory and the App Store Launch Asset Generator on MCP Market are also worth bookmarking. But the five above are the spine that covers all seven automation layers.
How do you run automated keyword research with Claude Code?
Automated keyword research with Claude Code follows a five-step orchestration pattern that turns a two-day analyst exercise into a 20-minute Claude session returning better-structured output than most humans would produce.
The workflow shape, as detailed in Stormy.ai's "Automate ASO Keyword Research with Claude Code in 20 Minutes":
- Operator hands Claude a seed keyword list and a competitor list.
- Claude queries Apple Search Ads and SerpAPI for live search results and store ranking positions.
- The ASO-MCP server pulls volume estimates and difficulty scores.
- Claude performs gap analysis: which keywords do competitors rank for that you do not?
- Claude returns a ranked recommendations table with confidence scores.
A representative research prompt:
You are my ASO research agent. The app is a Pomodoro timer for
remote teams. Seed keywords: pomodoro, focus timer, productivity timer.
Top three competitors: Forest, Focus Keeper, Be Focused.
1. For each seed, pull live search volume and competition from ASO-MCP.
2. Pull current top 50 ranking results from SerpAPI for each seed.
3. Identify keywords where competitors rank in top 10 and I rank below 50.
4. Cluster those gap keywords by intent group.
5. Return the top 20 ranked by (volume × gap_score) / difficulty.
The reason this works is that the underlying ranking and volume APIs were always available — what was missing was the operator-grade orchestration layer. Claude with the right MCP servers is exactly that orchestrator. We have run versions of this workflow on more than a dozen apps over the last quarter. Time-to-insight is typically under 25 minutes for a full keyword universe of 100-200 candidates.
If you do not have budget for SerpAPI, RespectASO is a free open-source iOS ASO keyword research tool you can wire into a Claude workflow. It is not as deep as the paid options, but it is genuinely usable for a small team. For ongoing competitive tracking, we combine the alirezarezvani research sub-agent with weekly competitor metadata snapshots — the gap analysis surfaces strategic intent shifts before they show up in category rankings. Visit our advanced ASO strategies guide for the full keyword universe-building methodology.
The deeper point: keyword research stopped being a moat the same way SQL stopped being a moat ten years ago. The orchestration layer got cheap, and what mattered shifted to the quality of the question being asked. The operators winning keyword research right now are not the ones with the best dashboard subscriptions — they are the ones with the most precise briefs.
How do you generate character-aware metadata that actually ranks?
Character-aware metadata generation is where craft still separates good operators from great ones — anyone can ask Claude to "write a good app title," but almost no one writes prompts that produce listing copy that actually ranks and converts.
First, the character limits that matter on iOS:
- Title: 30 characters
- Subtitle: 30 characters
- Keywords field: 100 characters, comma-separated, not visible to users
- Description: 4,000 characters
Google Play runs 50 / 80 / 4,000. The numbers differ but the discipline is identical: every character is a tradeoff between keyword coverage and human readability. It is also worth noting that Apple themselves use a large language model pipeline on the ingestion side of the store — Apple ML's published research on review summarisation describes a LoRA-fine-tuned model that generates the review summaries visible at the top of every app page. Refusing to run an LLM pipeline on the production side of your listing is a strange asymmetry given what is happening on the ingestion side.
The metadata generation prompt template we use in production:
Write App Store metadata for the following app. Hard constraints:
- title: <= 30 chars, must include keyword "{primary_kw}"
- subtitle: <= 30 chars, must NOT repeat title keywords,
must include one of {secondary_kws}
- keywords: <= 100 chars total, comma-separated, no spaces after commas,
no duplicates with title/subtitle, no plurals if singular already covered
- description: <= 4000 chars, first 170 chars (the "above the fold")
must contain primary value prop and {primary_kw}
App brief: {brief}
Competitor titles for reference: {competitor_titles}
Validate every character count before returning. If any field exceeds
its limit, regenerate that field only.
The validation instruction at the end is the secret. Without it, Claude will return a title of 33 characters because it counted tokens rather than characters. With the explicit validate-then-regenerate instruction, we get pass-the-first-time output roughly 95% of the time across our portfolio. The TimBroddin skill wraps this validation logic into an enforced constraint rather than a prompt instruction — which is even more reliable for high-volume metadata pipelines.
The deeper craft point: do not let Claude optimise for keyword density. Optimise for what the user reads in the first three seconds of seeing your listing. The keyword-stuffing era ended when both stores updated their spam detection in 2024. A title that reads naturally and includes one strong keyword beats a title that crams three weak ones — every time. Our complete ASO optimisation guide covers the metadata hierarchy for both stores in full.
One additional technique worth noting: the Apple Custom Product Pages feature allows up to 35 distinct listing variants, each independently optimisable for a different audience or campaign. We use Claude to generate metadata variants for each page, pairing keyword research with audience intent mapping to cover different acquisition contexts without diluting the primary listing.
How do screenshots directly drive Day-1 retention?
Screenshots are the single highest-leverage ASO surface in 2026 — and with stores now reweighting toward Day 7 retention, the install you do not get is the install that cannot retain, which means Day-1 retention starts before the user has tapped Install.
The mechanism: when the store reweights toward retention, the listing's job changes. It is no longer enough to maximise tap-Install rate. The listing now needs to set up the user to actually launch the app on Day 2, Day 3, Day 7. An honest screenshot that matches what the user will find inside the app delivers a user who is prepared and engaged. An overpromise delivers a user who churns within 24 hours and tanks your store ranking. The screenshot is the contract.
The cleanest implementation we have seen for automating this is Screenshot Whale. Their distinguishing capability is that it reads your codebase to extract your colour palette, app name, and design language, then writes benefit-driven copy. Not "Settings Screen" but "Make It Yours." That single example captures the default failure mode of human-written screenshot captions: they are descriptive labels. "Track Your Progress," "View Your Stats," "Customise Settings." Each is technically accurate and conversion-dead. The Claude-rewritten version turns each into a benefit promise. AppsFlyer's Performance Index data consistently shows that apps with benefit-led screenshot copy outperform feature-led copy on store conversion by 15-25% within the same category.
Other repos worth knowing:
- adamlyttleapps/claude-skill-aso-appstore-screenshots — opinionated about layout templates and benefit-led copy. Good defaults for teams without strong design opinions.
- ParthJadhav/app-store-screenshots — more flexible, more configuration overhead. Good for teams with strong design systems.
- App Store Launch Asset Generator (MCP Market) — combines ASO descriptions, keywords, localised templates, and screenshots into a single asset bundle.
A practical workflow we run across our portfolio: generate three rounds of caption variants per screen — benefit-led, social-proof-led, and feature-led — then A/B them against competitor screenshots from the Day 1 competitor map. The benefit-led variant wins roughly 70% of these A/B tests. The 30% where it does not are almost always apps where the primary value is credibility-based (finance, health) rather than transformation-based — those categories respond better to social proof framing. See our case studies for conversion lift data from specific screenshot A/B tests.
For localised screenshots, a common mistake is translating the English caption rather than rewriting it for the local market. Claude with a locale-specific system prompt will produce idiomatically correct local-language caption copy; direct translation tools produce captions that read as translated and convert poorly. Localised screenshots can add 15-30% conversion lift on top of localised metadata in markets where the visual language diverges significantly from Western conventions — Japan and South Korea being the most pronounced examples in our data.
How do you run rejection prevention with cruisediary's 31 checks?
In 2026, rejection prevention is the highest-ROI layer in the entire ASO stack — and the cruisediary/apple-app-review-skills repo's 31 checks, built from real rejection cases, are the most comprehensive pre-submission tool available to an independent operator.
The reason rejection prevention matters more in 2026 than it ever has: three enforcement shifts from Apple since Q1 2026 have materially raised rejection rates for AI-adjacent apps.
Guideline 2.5.2 — Apple has been actively blocking updates for AI apps that are thin wrappers around model APIs with cosmetic UI. If your app's primary functionality is a reskinned API call without differentiated UX, Apple is now more likely to reject the update than approve it. The cruisediary skill includes specific checks for the UI-depth patterns Apple is flagging under this guideline.
Guideline 5.1.2(i) — the AI data sharing rule that affects every iOS developer using a third-party model API. If your app sends user input to Anthropic, OpenAI, Google, or any third-party model provider, you must name the provider in your privacy disclosures. The number of rejections we have watched our network of app operators absorb for missing this disclosure is significant — it is a new requirement that most App Store compliance checklists do not yet include.
April 2026 submission changes — new mandatory fields for AI usage disclosure, tighter enforcement of trial conversion language, and new disclosure requirements for streaming subscription models. The throughput cost of an Apple rejection — typically one to two weeks of lost launch momentum — exceeds the cost of every other ASO mistake combined.
The cruisediary workflow we run before every submission:
Run cruisediary:apple-app-review-skills against:
- Info.plist
- App Store Connect metadata draft
- Screenshots (image content + caption text)
- Privacy nutrition label
- Subscription/IAP configuration
Output: Pass / Conditional / Block per check, with citation
to the specific Review Guideline section and the rejection case
that motivated the check.
Resolve every Block before submitting.
Discuss every Conditional with the team.
The 31 checks span all five sections of the Apple App Store Review Guidelines:
- Section 1 (Safety) — privacy nutrition labels misaligned with actual SDK behaviour.
- Section 2 (Performance) — crashes on launch, broken sign-in, features behind paywalls that are unclear about cost.
- Section 3 (Business) — subscription disclosure language that is technically present but not above the buy button.
- Section 4 (Design) — screenshot quality, status bar inconsistencies, illegal sample data.
- Section 5 (Legal) — third-party content rights and, increasingly, AI data sharing disclosure under 5.1.2(i).
If you do nothing else recommended in this guide, run cruisediary before your next submission. The return on a 20-minute pre-flight check against a one-to-two-week rejection delay is not a close calculation. Our broader App Store algorithm 2026 guide covers how the enforcement changes interact with ranking signals in more detail.
What does a high-leverage one-week ASO sprint look like?
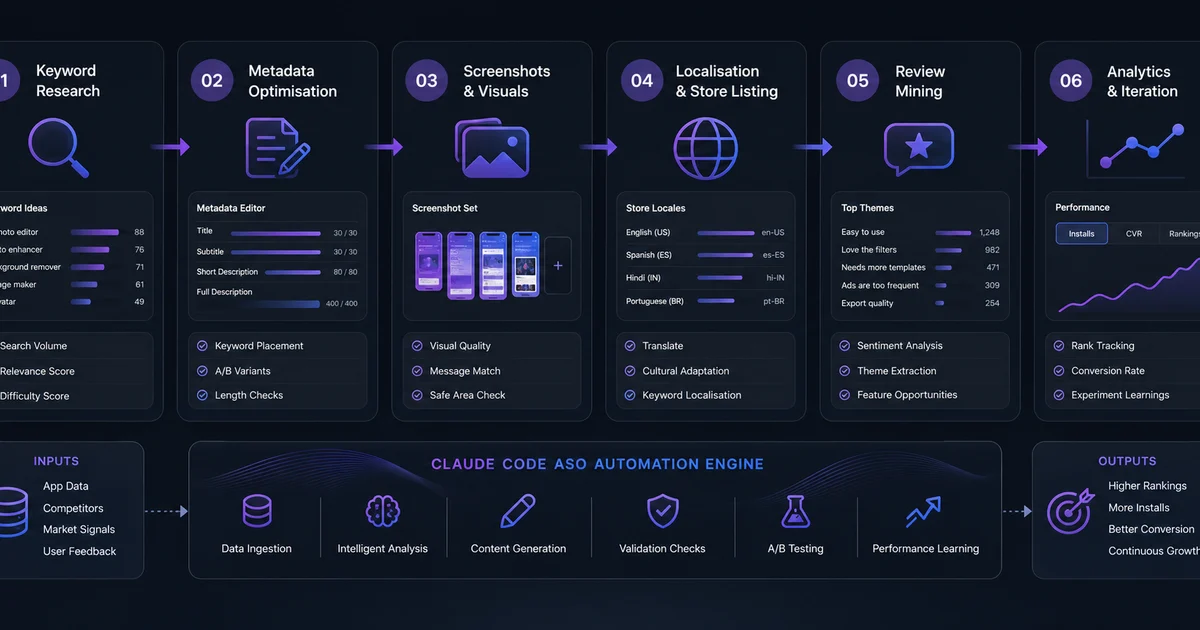
A high-leverage ASO sprint with the full Claude skill stack takes one focused operator roughly five working days for the first run of a new app, and three days by the third sprint cycle — covering all seven automation layers in sequence.
Day 1 — Setup and competitor map. Install the skills. Connect the iTunes Search API. Wire up SerpAPI or ASO-MCP for keyword data. Configure Claude Code with the core skill stack — typically alirezarezvani, cruisediary, and Screenshot Whale as the core three, with dock-aso as the process orchestrator. Run the competitor map: pull the top 10 competitors in your category, snapshot their metadata, snapshot their screenshots, snapshot their last 100 reviews. By end of Day 1 you have a structured artefact — who you are competing against, what they are claiming, what users are praising or complaining about.
Day 2 — Metadata in five languages. Run keyword research for the primary locale (typically en-US). Generate metadata draft. Validate character counts. Then run the localisation pipeline — we target en-US, ja-JP, de-DE, fr-FR, and es-ES as a standard starting five. If the app has a Southeast Asia tilt, swap one European locale for id-ID or vi-VN. Each locale gets a Claude-drafted pass followed by a native-speaker QA review. By end of Day 2 you have submission-ready metadata in five markets. AppTweak's localisation research benchmarks localised listings at a 38% average download lift — the one-day cost of this step pays back in the first two weeks of expanded distribution.
Day 3 — Screenshots. Run Screenshot Whale or adamlyttleapps' generator against the codebase. Generate three rounds of variants per screen — benefit-led captions, social-proof-led captions, feature-led captions. A/B them mentally against the competitor screenshots from Day 1. End of Day 3: localised screenshots in five markets, three caption variants per screen, ready to plug into App Store Connect.
Day 4 — Submission review pass. Run cruisediary's 31 checks against the full submission package. Resolve every Block. Discuss every Conditional with the team. This day is almost entirely about catching the mistake that costs you a week of rejection-resubmit cycle. Do not skip it.
Day 5 — Submit.
Days 6-7 — Review mining and next-sprint planning. While the app is in review, mine the last 30 days of reviews on competitors. Build the next sprint's feature backlog from the patterns — clusters of feature requests that appear in competitor reviews and are absent from your own listing are the highest-signal inputs for both product roadmap and subtitle refresh. Plan the next metadata refresh cycle.
The sprint cycles every 4-6 weeks for an active app. By the third cycle the entire workflow takes approximately three working days. In our portfolio, apps that run quarterly ASO sprints with this stack produce organic install rates that are 2-3x higher than apps running annual or ad-hoc ASO work — the compounding effect of monthly metadata iteration is one of the most consistent findings we have across 300+ apps managed since 2013.
If you want this stack running on your app without building it in-house, our ASO service runs this exact sprint structure. Our user acquisition service layers paid UA strategy on top of the organic foundation the sprint produces. And if you want to see what the combined approach delivers in practice, the numbers are in our client results. Talk to our team to scope a sprint for your specific app and category.
Frequently Asked Questions
Do I need to pay for AppTweak or Sensor Tower to use Claude-based ASO automation?+
Not necessarily. The alirezarezvani four-subagent stack uses the iTunes Search API (free, no key required) plus WebFetch calls for competitor intel, covering roughly 80% of standard keyword and competitor research at zero marginal cost beyond Claude tokens. The paid SaaS tools retain one moat: deep historical ranking data, which requires continuous polling that the open-source stacks do not maintain. If ranking history is core to your strategy, keep the SaaS subscription. If you primarily need metadata diffs and qualitative competitor intelligence, the Claude stack is sufficient.
How long does a full seven-layer ASO sprint take?+
The first sprint on a new app takes roughly five working days for one operator. By the third sprint cycle, once the skill stack is configured and the competitor baseline is established, the full workflow compresses to approximately three working days. The setup overhead is front-loaded; subsequent cycles are materially faster.
What is Guideline 5.1.2(i) and does it affect my app?+
Guideline 5.1.2(i) is Apple's AI data sharing rule requiring that any app sending user input to a third-party model provider — Anthropic, OpenAI, Google, and others — must explicitly name that provider in its privacy disclosures. If your app has any AI feature powered by an external API, you are affected. The cruisediary rejection-prevention skill includes a specific check for this guideline, and it has been one of the most frequently triggered checks since Apple began enforcing it aggressively in Q1 2026.
Is AI-generated localisation reliable enough to use in production?+
Claude produces localised ASO copy that is materially better than generic machine translation for App Store listing formats, which are keyword-aware, character-limit-aware, and require culturally correct idiom rather than literal translation. ASO.dev rates Claude above Google Translate for App Store copy specifically. That said, we always pair Claude-drafted localisation with a native-speaker QA pass before submitting to a major market. The combination of Claude-drafted plus native-speaker-reviewed is approximately 10x cheaper than full agency translation and noticeably better than either alone.
How does the retention reweighting change what I should put in my screenshots?+
It means the screenshot's job is no longer simply to maximise tap-Install rate — it is to attract users whose expectations match what the app actually delivers inside. An overpromise that drives installs now actively harms ranking because those installs churn and depress your Day 7 retention signal. Benefit-led screenshot copy that accurately represents the app's core value proposition performs better under the updated algorithm than aspirational copy designed to maximise conversion rate at the expense of retention fit.
What does Vmobify do for ASO specifically?+
We run the full seven-layer ASO sprint described in this guide across our client portfolio — keyword research, character-aware metadata generation, benefit-led screenshot copy, localisation in five or more markets, competitor intelligence, review mining, and pre-submission rejection prevention using cruisediary's 31 checks. Our ASO service is fully integrated with our user acquisition work, so the organic foundation and the paid layer are built as one system. Details and case studies are at /services/aso and /results.
What is the single biggest ASO mistake teams make in 2026?+
Skipping rejection prevention and submitting without running a pre-flight check. The throughput cost of a single Apple rejection — one to two weeks of lost launch momentum, sometimes more — exceeds the cost of every other ASO mistake combined. Running cruisediary's 31 checks takes 20 minutes. The ROI on that 20 minutes is not a close calculation, and yet most teams still skip it.
Sources
- Apple App Store Review Guidelines — Official rejection criteria and AI app policies (Guideline 2.5.2 and 5.1.2(i))
- Apple Custom Product Pages — iOS-native paid UA conversion optimisation surface — up to 35 independently optimisable listing variants
- Apple Search Ads — Keyword intelligence from the first-party iOS UA platform
- Apple ML — App Store Review Summarisation — Apple's own LLM pipeline for review summarisation — validates the approach on the ingestion side
- AppsFlyer Performance Index — CPI benchmarks and category ranking signals including retention reweighting data
- Sensor Tower App Intelligence — App store keyword and ranking intelligence; historical data depth is primary moat over open-source stacks
- AppTweak ASO Platform — ASO keyword research and competitor metadata analysis; localisation lift benchmarks
- SplitMetrics A/B Testing — App Store product page A/B testing platform; first-screenshot conversion impact data
About the author
Amol Pomane — Founder, Vmobify
Amol leads Vmobify, a mobile app growth agency that has driven 30M+ downloads and ranked 54K+ keywords across 300+ apps since 2013. He writes about ASO, paid user acquisition, retention, and the operational reality of scaling mobile apps in India and global markets.
Free Growth Audit
See exactly how to scale your app with 13+ years of expertise behind you.
Get My Strategy

